New preprint: Optimizing policies based on thresholds
Here Sofia Triantafillou, Konrad Kording and I present a new method for optimizing policies that are based on simple thresholds, using theory from contextual linear bandits.
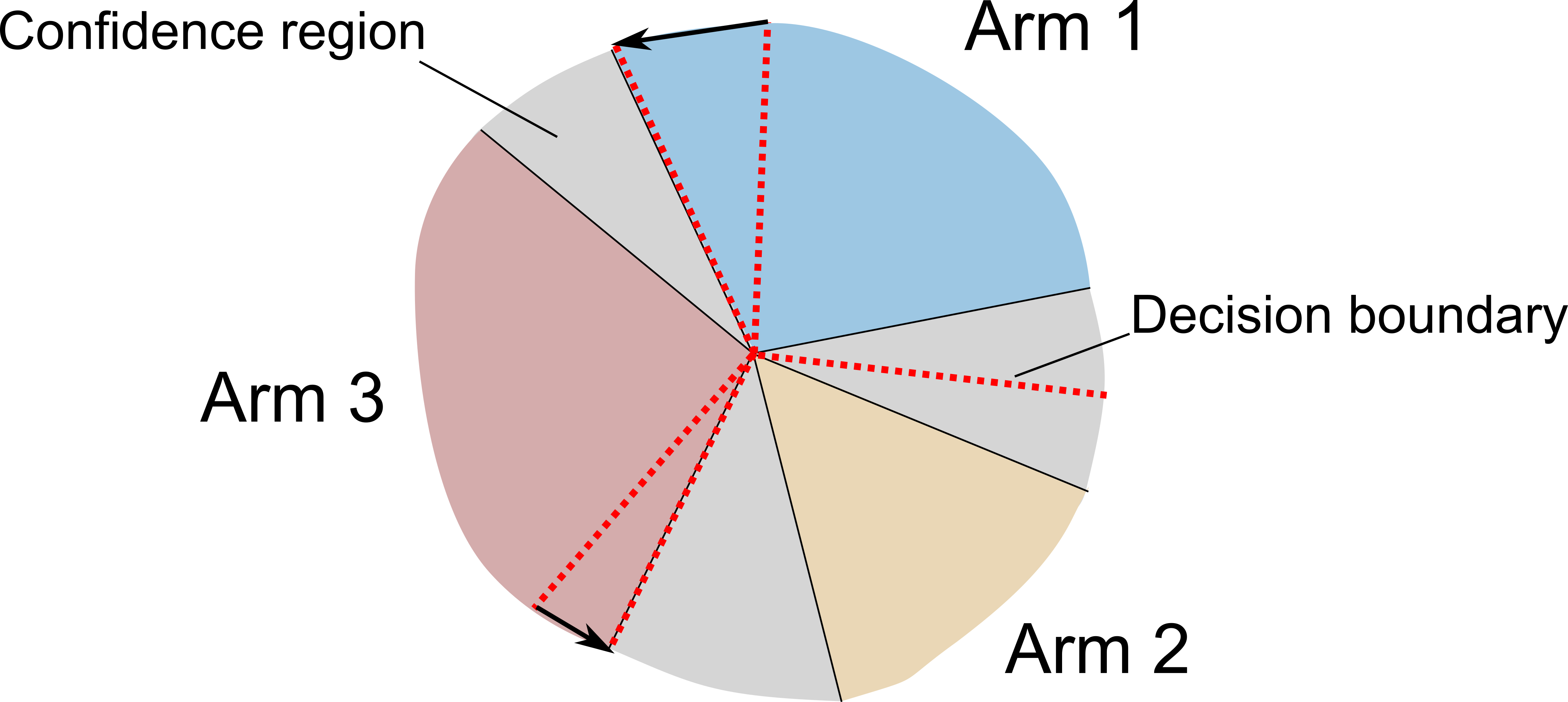
Excessively changing policies in many real world scenarios is difficult, unethical, or expensive. After all, doctor guidelines, tax codes, and price lists can only be reprinted so often. We may thus want to only change a policy when it is probable that the change is beneficial. In cases that a policy is a threshold on contextual variables we can estimate causal effects for populations lying at the threshold. This allows for a schedule of incremental policy updates that let us optimize a policy while making few detrimental changes. Using this idea, and the theory of linear contextual bandits, we present a conservative policy updating procedure which updates a deterministic policy only when justified. We provide simulations and an analysis of an infant health well-being causal inference dataset, showing the algorithm efficiently learns a good policy with few changes. Our approach allows efficiently solving problems where excessive changes are to be avoided, with applications in medicine, economics and beyond.
Check it out here: Lansdell B, Triantafillou S, Kording K, arXiv 2019